
Рейтинг статьи: 5,00 

Технические ошибки и недочеты в оптимизации можно найти на любом сайте – и это абсолютно нормально. Проектам свойственна постоянная динамика: они обновляются, меняют структуру, переиндексируются, получают ссылочные сигналы – на фоне этих процессов неизбежно возникают те или иные бреши в техническом SEO. Но когда проблемы становятся критическими, приобретают массовый характер и начинают влиять на ранжирование – это уже плохо. Такие уязвимости нужно своевременно обнаруживать и устранять. Именно поэтому время от времени следует вспоминать про глубокий технический аудит для своего ресурса.
SEO-ошибки возникают не только по мере естественного развития сайта. Они могут быть заложены еще на этапе создания проекта или носить накопительный характер, и в полной мере заявить о себе со временем, когда сайт нарастит основные показатели. Еще чаще SEO-проблемы выстреливают из-за неумелых действий оптимизаторов, а иногда к этому прикладывают руку и недобросовестные конкуренты.
В этом материале мы последовательно пройдемся по самым часто встречаемым SEO-ошибкам, расскажем, как они появляются, влияют на ранжирование и главное – как их правильно исправлять.
Дубли – это страницы, которые имеют свой уникальный URL-адрес, но наполнены идентичным или очень похожим контентом. Дубли бывают полными и неполными (частичными), когда содержимое страниц совпадает в среднем на 85% и более. И те и другие очень не нравятся поисковикам и являются серьезным недочетом внутренней оптимизации. Отдельно отметим, что дубли – это не только о текстах, но и про другие виды контента: повторяющиеся видео, изображения или метатеги.
В большинстве случаев они возникают не из-за прямых действий вебмастеров, а по техническим причинам: из-за особенностей настроек CMS, работы некоторых плагинов, верстки шаблона; массовые дубли часто выстреливают после изменения структуры сайта, редизайна и проведения других крупных технических работ.
Если говорить о человеческом факторе, причиной дублей часто становятся некорректно настроенные (или слетевшие и незамеченные) редиректы, страницы пагинации с непрописанным каноникалом. Дубли также могут возникать из-за однотипных title, что обычно происходит на страницах с незначительным содержимым, например, с товарными карточками, у которых заголовки массово сгенерированы через шаблон.
Через уведомление в Вебмастере
Яндекс.Вебмастер сообщает о наличии дублей автоматически. Проверяют это оповещение в разделе «Диагностика». Подписываться на уведомления не нужно, они появляются сами, правда, это может происходить с незначительной задержкой, в два-три дня.
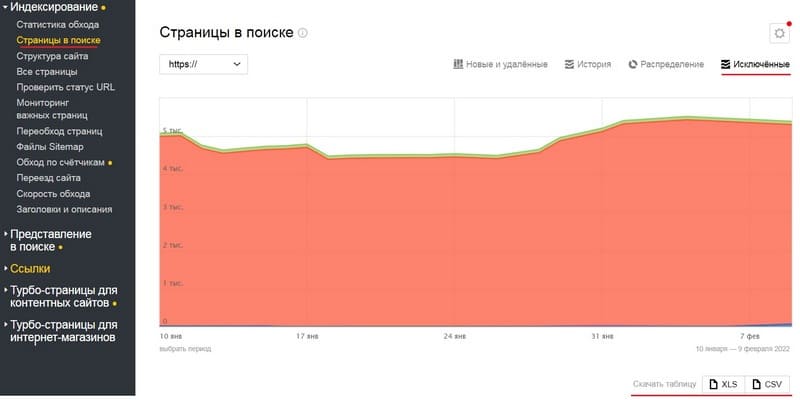
Вручную в Вебмастере
То же самое можно сделать по старинке: открываем вкладку «Индексирование» → «Страницы в поиске». Справа вверху нажимаем «Исключённые». Скачиваем архив в подходящем формате – в файле все проблемные URL будут иметь статус DUPLICATE.
SEO-краулерами
Просканировать сайт на предмет дублей также можно специальными программами. Вебмастера традиционно используют: Screaming Frog, Xenu`s Link Sleuth, Netpeak Spider, Ahrefs (на самом деле, софта для таких задач достаточно много). При проведении глубокого аудита лучше использовать именно сторонние программы, а не данные из вебмастерок.
— добавить rel=canonical, чтобы указать поисковикам основную страницу из перечня дублей, которую нужно показывать в результатах поиска;
— настроить 301-й редирект со второстепенной страницы на основную версию (это имеет смысл, если с дубля идет трафик или у него есть качественные обратные ссылки);
— расширить и уникализировать контент на однотипных страницах;
— удалить ненужные URL, если они не приносят трафик, не имеют обратных ссылок и бесполезны для пользователей.
В случае с дублями главное – всегда пытаться понять причину, которая приводит к генерации однотипных страниц, и своевременно решать ее.
Технически здесь идет речь о тех же дублях, только не на уровне контента, а на уровне поисковых запросов. Если проще, так происходит, когда берут группу одинаковых (или очень похожих) ключевых слов и начинают использовать их на разных страницах сайта. Это вводит Google и Яндекс в заблуждение, и они просто не знают, какую из страниц отображать по релевантному запросу. Как и с дублями, поисковики в таком случае оставляют в индексе только одну из страниц, и никто не гарантирует, что это будет самая качественная версия.
Как результат, на сайтах с каннибализацией часто по основным запросам ранжируются второстепенные страницы, а приоритетные разделы вовсе вылетают из индекса и не получают поискового трафика. При этом визиты на некачественные версии страниц дают лишь много отказов, короткое время сеансов, низкую глубину просмотров. Итог всего этого: не просто отсутствие конверсий с целевой страницы, но и постепенная пессимизация всего сайта из-за общей просадки поведенческих. Таким образом, когда много страниц начинает конкурировать между собой – это очень плохо для внутренней оптимизации.
В отличие от дублей, причины каннибализации никак не связаны с технической частью, а в абсолютном большинстве случаев возникают по недосмотру оптимизаторов. Как правило, здесь имеет место один из следующих сценариев неправильной работы с семантикой.
1. Добавление новых разделов и наполнение сайта контентом осуществляют без использования семантического ядра. Другими словами, с поисковыми запросами работают интуитивно, без четкой структуры и плана действий.
2. Семантика собрана очень поверхностно и/или неправильно произведена ее кластеризация (как вариант – этого вовсе не сделано), из-за чего ключи неэффективно распределены по посадочным страницам. Объясним на пальцах: оптимизатор может создать две страницы под запросы, например, «SEO продвижение» и «SEO раскрутка»; формально – это разные ключи, но для поисковых систем они семантически идентичны, и одна из страниц, скорее всего, вылетит из индекса. Это было бы очевидным при грамотно проведенной кластеризации.
3. Естественная каннибализация, возникающая по мере увеличения контента на сайте. Даже при условии грамотно спланированной контент-политики, на сайтах с большим объемом публикаций, часто появляются материалы, со взаимно конкурирующими ключами, что приводит к проблемам с ранжированием одной из страниц.
Как видно, каннибализация далеко не всегда всплывает из-за косяков оптимизаторов. Потому важно время от времени проверять сайт на наличие таких проблем и исправлять их. Подробнее о том, как это делать – рекомендуем почитать в отдельном материале.
Ошибка – очень банальная. Чаще она имеет место, когда с сайтом вообще не велись какие-либо работы по оптимизации. Но есть и другие причины. Ни для кого не секрет, что тайтл – это очень важный элемент. Он подтягивается в заголовок сниппета и является первым, что видят пользователи на выдаче. Таким образом, он оказывает абсолютное влияние на CTR.
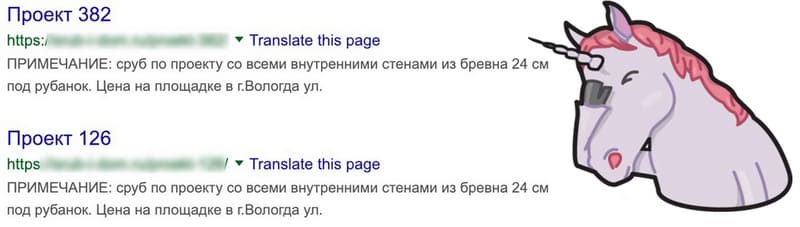
Самая грубая и банальная ошибка – это незаполненные тайтлы. Поисковики сами пофиксят проблему, и сгенерируют заголовок сниппета автоматически, но за его качество и информативность никто не будет нести ответственность; и уж точно вряд ли поисковые алгоритмы оптимизируют ваши тайтлы под ключи, что тоже очень важно.
Тайтлы могут слетать из-за технического сбоя. Часто такое происходит, когда вебмастера пытаются вставить в заголовок эмодзи – многие CMS не настроены на корректную обработку подобных спецсимволов – в результате чего слетает весь тайтл. В итоге страница публикуется с незаполненным заголовком и такая проблема обычно долгое время остается незамеченной. Аналогичное может произойти при сбоях в работе или неправильных настройках шаблонов автогенерации title, которые часто используют на сайтах с большим количеством страниц.
Как видим, проблемы с тайтлами – это не только про ошибки новичков, поэтому заголовкам нужно время от времени проводить аудит. Коротко о том, что еще смотреть при проверке.
✔ Слишком короткие/длинные описания: оптимальная длина title – 51-60 символов.
✔ Повторяющиеся тайтлы на разных страницах.
✔ Неуникальные метатеги, массово спарсенные у конкурентов.
✔ Неправильная работа с семантикой: переспам ключами (одного ВЧ-запроса вполне достаточно), наличие окружения со спамным окрасом (например, слов «лучший», «дешевый» и пр.), отсутствие ГЕО, если оно актуально.
✔ Нерелевантность title содержимому страницы.
Здесь стоит напомнить, что в 2021 году Google радикально пересмотрел свои подходы к обработке тегов Title. Если коротко: он стал намного чаще пренебрегать заполненной информацией и генерировать заголовки самостоятельно. Но даже несмотря на это, все равно очень важно продолжать оптимизировать тайтлы в соответствии с общепринятыми требованиями. Подробнее на эту тему – читайте в отдельном материале:
Как Google изменяет тайтлы. Пересказываем результаты нового (и весьма убедительного) исследования
Непроработанные H1 – еще один часто встречаемый недочет внутренней оптимизации. Как правило, на сайтах эта проблема идет рука об руку с плохо оптимизированными тайтлами, но решают ее несколько иными способами. Коротко о том, какие ошибки совершают при работе с H1 и как их исправить:
Как ни странно, такая проблема встречается часто. Страницы без H1 могут индексироваться и отображаться в результатах Google и Яндекса, но поисковики в этом недополучат ценные SEO-сигналы. При прочих равных алгоритмы всегда будут лучше ранжировать страницы с оптимизированными H1, предоставляя им более высокие позиции в выдаче.
H1 оптимизируют с оглядкой на Title: два заголовка делают разными, но не противоречащими друг другу по смыслу, чтобы поисковики не путались, с каким из запросов соотносить страницу. Это не жесткое правило, а скорее рекомендация, которая тем не менее закрепилась как общепринятая сеошная норма. В H1 вписывают второй по важности ключ из кластера запросов, под который оптимизируют страницу, а главный ВЧ-запрос отводят под тайтл. В обоих заголовках можно использовать одинаковый ключ, но в этом случае желательно вписывать его в разных словоформах. Как и с Title, при оптимизации H1 важно не спамить: одного-двух вхождений ключевого слова – вполне достаточно.
В отличие от других заголовков, H1 используют на странице только один раз. Множественное повторение H1 обесценивает сигналы, которые алгоритмы получают через этот важный тег. В лучшем случае это может «распылить» SEO-ценность H1, в худшем – поисковики посчитают страницу спамной и неинформативной. Сам H1 помещают как можно ближе к началу HTML-документа и не повторяют его на других страницах.
Работая с заголовками разного уровня, важно соблюдать их логическую иерархию. Непоследовательное расположение Н2, Н3, H4 и т. д. нельзя назвать очень серьезной ошибкой, но это может влиять на то, как поисковые алгоритмы понимают структуру документа и определяют общую релевантность страницы.
Оптимизация картинок – самый простой способ расширить присутствие сайта в поиске и получать дополнительный трафик. То, что принято называть Image SEO, не требует от вебмастеров больших усилий и системной работы, но многие продолжают пренебрегать им. При этом, если для обычных сайтов оптимизация картинок – в большей степени рекомендация, то для тех же магазинов – это уже критически важный компонент внутристраничного SEO.
Оценить общую долю картиночного трафика и другие показатели, связанные с переходами по изображениям, можно в Google Search Console:
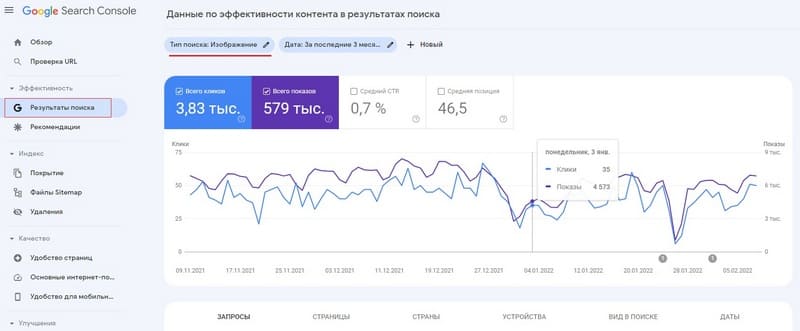
Эффективность → Результаты поиска → Тип поиска: Изображение
Прописанные альты с релевантными ключами – половина успеха для оптимизации картинок. Альтернативное описание должно отражать содержание фото, иметь вхождение релевантного ВЧ-запроса и не превышать 100-120 символов. Все банально, просто – и при этом действительно эффективно. Картинкам можно не прописывать тайтлы и пренебречь другими деталями оптимизации, но пустые атрибуты alt – это серьезный просчет. Отдельно отметим, что в Яндексe альты важны только для поиска по изображениям, в то время как в Google эти атрибуты дополнительно влияют на ранжирование в основной выдаче.
Больше практических рекомендаций по SEO для изображений – читайте в отдельной статье.
Структуру URL-адресов на любом сайте всегда приводят к удобочитаемому ЧПУ-формату. Избегайте, чтобы URL выглядели как бессодержательный набор символов — они должны иметь вид коротких, понятных и легко читаемых идентификаторов. В противном случае это затруднит обход страниц поисковыми краулерами, что, в свою очередь, повлечет проблемы с индексированием и ранжированием в поиске.

Человекопонятные урлы также важны для обычных людей, поскольку часто они выступают в роли своего рода вспомогательной навигации, когда, смотря на адрес, пользователь понимает, на каком уровне вложенности он сейчас находится. Другими словами, работает тот же эффект, что и с «хлебными крошками». В дополнение к этому сниппет с ЧПУ выглядит более привлекательным и информативным на выдаче — и это отражается на CTR.
![]()
![]()
Таким образом, настройка ЧПУ как прямо (через индексирование), так и косвенно (через поведенческие) определяет качество поисковой оптимизации.
Любые страницы сайта можно закрывать от индексирования – поисковые роботы не смогут сканировать такие документы и отображать их в выдаче. Так, например, часто поступают с техническими страницами, которые не хотят делать общедоступными. Но бывают случаи, когда по незнанию или по ошибке от обхода закрывают важные разделы. Очевидно, что это критическая проблема, т. к. недоступные для индексирования страницы не приносят поискового трафика и делают все усилия по SEO-продвижению бесполезными.
Запретить Google и Яндексу индексировать документы можно разными способами:
Закрывать отдельные страницы (или целые разделы) можно не полностью, а частично, задавая более гибкие настройки индексирования. Например, иногда делают так, чтобы поисковые роботы не учитывали страницу, но индексировали ссылки на ней. Подробнее о каждом из трех способов, а также о том, какие страницы нужно закрывать от роботов Google и Яндекса – читайте здесь.
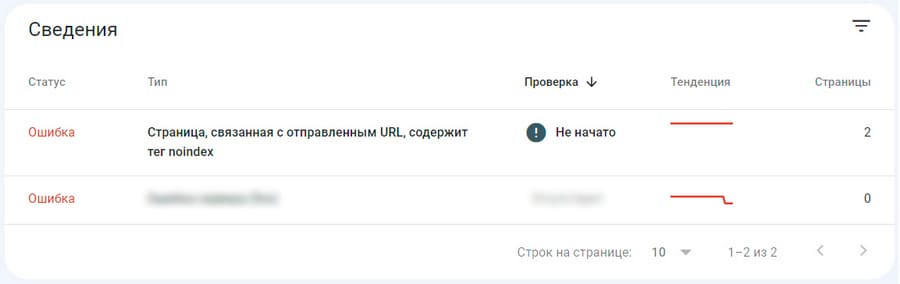
Со временем на сайте накапливается много настроек индексирования – и за ними нужно следить. Есть разные сценарии, когда что-то может пойти не так. Указанные директивы могут просто слететь. Часто такое происходит после глобальных обновлений на сайте: изменения структуры, переноса на новый движок и пр. Никто не исключает и банальных оплошностей, например, когда вебмастер по ошибке закрывает не то что нужно или забывает восстановить доступ к страницам, который был ограничен на период технических работ. Отдельно стоит сказать про настройки индексирования через Robots.txt: здесь часто бывает так, что из-за некорректно прописанной директивы, непреднамеренно закрывают доступ не к отдельным страницам, а целым разделам.
Когда такие ошибки долгое время остаются незамеченными, это приводит к печальным последствиям с поисковым трафиком. Перестраховаться от подобного рода неприятностей достаточно просто: нужно привязать сайт к Яндекс.Вебмастеру и/или Google Search Console и отслеживать все уведомления. При необходимости настройки индексирования в вебмастерках всегда можно проверить вручную. Больше об управлении индексированием – читайте в отдельной статье.
Вместо штатных инструментов Я.Вебмастер и Search Console, для проверки статуса индексирования можно использовать и сторонние SEO-краулеры. Например, такое умеют делать Ahrefs, Screaming Frog, SEMrush и много других программ.
В SEO уделяют много внимания обратным ссылкам, и это понятно – сигналы с других сайтов очень важны для эффективного продвижения. Вместе с тем не стоит забывать и о внутреннем ссылочном профиле, оптимизация которого также в приоритете. Среди типичных ошибок и недочетов, связанных с внутренними ссылками, можно выделить следующие ситуации.
Страницы сайта связывают внутренними ссылками. В идеале, на каждую более или менее значимую страницу должна стоять минимум одна ссылка из другого раздела. Такая система называется перелинковкой, и она является важным компонентом внутренней оптимизации сайта. Если коротко, документы на которые не ссылаются другие страницы:
Создание грамотной перелинковки подчиняется некоторым правилам. Не вдаваясь в сложности: более авторитетные страницы сайта всегда должны ссылаться на менее трастовые документы. Но это далеко не все. Подробнее о том, как правильно линковать страницы – читайте в отдельной статье.
Перелинковку важно всегда поддерживать в актуальном состоянии, а чтобы найти разделы сайта, на которые не ссылаются другие страницы, используют уже упомянутые программы-краулеры: Screaming Frog, Netpeak Spider, Ahrefs и др.
Не стоит забывать, что внутренние ссылки – это не только перелинковка в текстах. Общее количество линков на странице зависит от особенностей верстки, а также специфики содержимого, например, листинги по умолчанию будут иметь больше ссылок, чем другие разделы. Из-за переизбытка ссылок возможны проблемы с краулинговым бюджетом, когда поисковым роботам не хватает лимитов на обход сайта. Это, в свою очередь, чревато сложностями с индексированием. Важно отметить, что подобные сценарии актуальны только для крупных сайтов: если ресурс содержит меньше 100 000 URL-адресов, о проблемах с краулинговым бюджетом можно забыть. Тем не менее, возвращаясь к основному вопросу, существует условный стандарт, что количество внутренних ссылок на странице не должно быть более 200.
Ссылаться на чужие сайты – это абсолютно естественно для экосистемы интернета, но и здесь имеются потенциальные риски, о которых следует знать. В первую очередь нужно ссылаться только на качественные сайты и страницы с тематически релевантным контентом. Помимо этого:
Все указанные атрибуты поддерживаются как Google, так и Яндексом. Подробнее об их использовании – в официальной справке.
Битые ссылки, которые ведут на страницы с ошибкой 404, не нравятся ни пользователям, ни поисковым алгоритмам. При этом их появление – вполне естественный процесс для всех сайтов, особенно тех, что активно обновляются. Критическая масса неработающих ссылок может пессимизировать поисковый рейтинг и точно не пойдет на пользу поведенческим факторам. Добавим сюда уже упомянутое перераспределение ссылочного веса и проблемы краулингового бюджета (для крупных сайтов) — после этого становится очевидным, что игнорировать неработающие ссылки не стоит.
Больше о том, чем опасны битые ссылки, как их находить и что делать дальше – читайте в отдельной статье.
С помощью ссылок из других источников можно быстро и эффективно раскачать поисковый авторитет своего сайта, но если не знать всех тонкостей этого процесса – неизбежны серьезные проблемы со стороны поисковиков, вплоть до самых фатальных. Линкбилдинг – это сложно и ответственно, именно поэтому он фактически выделился в отдельное направление SEO. Чтобы лучше понять его суть, рекомендуем ознакомиться с серией специальных материалов на эту тему. Здесь же мы лишь коротко перечислим те факторы, которые могут быть потенциальной проблемой и должны насторожить вебмастера при анализе ссылочного профиля:
1. Неестественно резкий рост количества обратных ссылок на сайт. Такая динамика с большой долей вероятности может свидетельствовать о ссылочном взрыве – приеме негативного SEO, с помощью которого конкуренты пытаются завести сайт под фильтр.

2. Наличие в ссылочном профиле подозрительных доноров. Здесь имеются в виду:
3. Большое количество ссылок с тематически нерелевантных площадок.
4. Прирост анкорных бэклинков, с вхождением ключевого слова. Такие ссылки наиболее опасные с т. з. наложения фильтра, и часто именно их используют как инструмент негативного SEO.
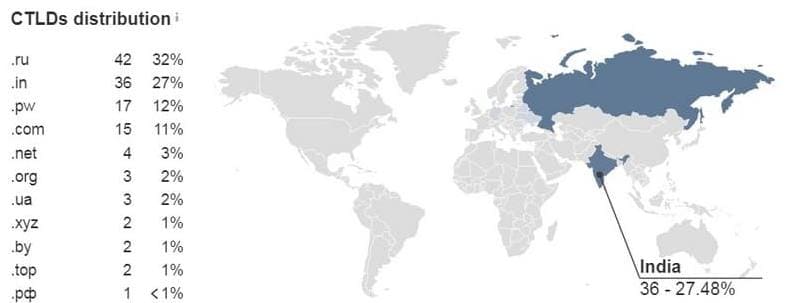
5. Множество обратных ссылок из подозрительных доменных зон.
Подробнее о том, как отслеживать потенциально опасные ссылки и что с ними делать дальше – читайте в отдельной статье.
Очень часто по незнанию или по каким-либо другим причинам владельцы сайтов игнорируют добавление т. н. технических страниц. Речь идет о пользовательском соглашении, политике конфиденциальности, страницах об авторах проекта. На первый взгляд, это, действительно, может показаться формальностью, но для поисковиков такие разделы являются важным сигналом доверия и качества. И это касается не только YMYL-сайтов, на которых необходимо соблюдать требования E—A—T.
Исправив этот недочет, любой ресурс может рассчитывать в среднем на +20-30% к трафику. Причем после добавления технических страниц все изменения происходят довольно резко.
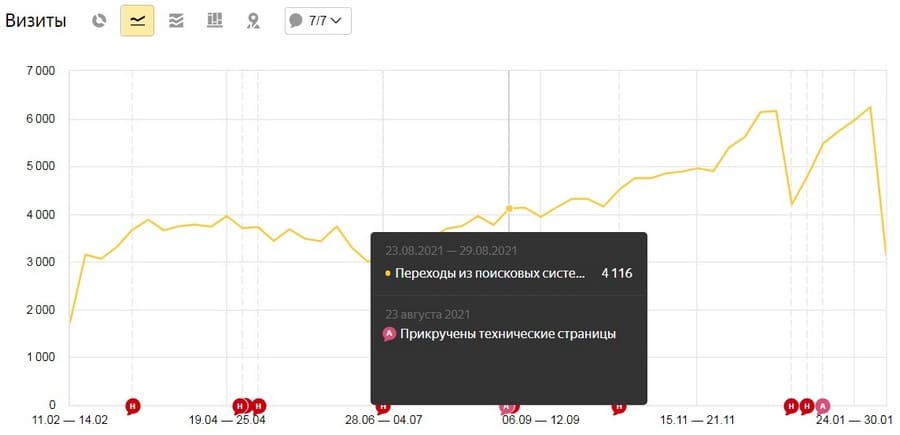
Если вы используете шаблонный текст пользовательского соглашения или политики конфиденциальности, по желанию, страницы с неуникальным содержимым можно закрыть от индексации, в большинстве случаев это никак не влияет на результат.
Речь идет о контенте, который не представляет фактической ценности для пользователей, а ориентирован в большей степени на поисковые системы. Это могут быть как просто короткие переоптимизированные тексты, которым не хватает глубины и полезности, так и технический «мусор», по недосмотру попавший в индекс. Неуникальные страницы, со скопированным и дублированным содержимым, также расцениваются как тонкий контент.
Любой из сценариев обработки такого контента поисковиками не принесет ничего хорошего. Алгоритмы либо просто посчитают страницу некачественной и удалят ее из индекса, либо отправят документ на самые далекие позиции в выдаче, т. к. не смогут правильно понять его содержания. Если страниц с тонким контентом много, в дело может вступить алгоритмическая пессимизация, которая распространяется уже не на отдельные URL, а на весь сайт.
В Google тонкий контент также часто становится причиной появления ложной ошибки 404 (soft 404). В этом случае страница физически существует (сервер помечает ее статусом OK), но для поисковика URL получает формальный статус 404 (страница не найдена). Вебмастека уведомляет об ошибке и со временем такие страницы вылетают из индекса.