
Рейтинг статьи: 5,00 

Яндекс и Google примерно поровну делят весь русскоязычный трафик. Хотя внешне они и похожи, каждая из поисковых систем функционирует по своим алгоритмам, с особенностями которых приходится считаться всем, кто продвигает сайты в Рунете. Поскольку это одна из фундаментальных тем в SEO, неудивительно, что она овеяна наибольшим количеством мифов и диаметрально противоположных мнений. Недавно вышла обстоятельная статья, в которой, вероятно, самый авторитетный голос русскоязычного SEO пробует внести окончательную ясность в вопрос отличий продвижения под Google и Яндекс. Это очень важная SEO-публикация – и мы кратко пересказываем главную ее часть (и местами что-то добавляем от себя).
Алгоритмы Google и Яндекса по-разному интерпретируют интент (намерение) поискового запроса. Это значит, что по одной и той же фразе в выдаче могут преобладать либо коммерческие сайты, либо информационные. Но утверждать, что какая-то из ПС более коммерчески ориентирована (выдает больше магазинов/сайтов услуг) – некорректно. Здесь все объясняется разницей понимания информационных потребностей.
Дополнительно поисковики классифицируют каждый сайт по ряду параметров: тематике, региональности, возрастным ограничениям и др. Работа классификаторов Google и Яндекса может кардинальным образом отличаться, например, в одной ПС сайт будет ранжироваться, как адалт, а в другой отображаться в безопасном поиске. Повлиять на это фактически никак нельзя, просто нужно быть в курсе.
Для эффективного ранжирования в Google решающее значение имеет качество мобильной версии сайта. Для Яндекса этот фактор тоже важен, но он далеко не главный. В Google работает модель индексирования Mobile First Index, в соответствии с которой приоритет отдается обработке данных с мобильной версии сайта (неважно, будь то просто адаптивный дизайн или отдельная версия под мобайл). Поэтому если seo-сигналы с мобайла слабые, то и ранжирование будет соответствующим.
Яндекс хоть и уделяет все больше внимания фактору мобилопригодности, но пока не использует подобный подход. При оценке сайта приоритет здесь по-прежнему отдается поведенческим метрикам с десктопа, что, естественно, не повод списывать со счетов работу над качеством мобильной версии.
Здесь Google и Яндекс идут наравне, и каждый из них предлагает свою технологию создания легких версий страниц под мобильный поиск. У Google это AMP, у Яндекса – турбо-страницы.
Две концепции в общих чертах очень похожи: исходные страницы унифицируются, получают легкую оптимизированную верстку, кэшируются на собственных серверах + дополнительное использование CDN-сетей. Результат – страницы грузятся несопоставимо быстрее, например, Яндекс уверяет в увеличении скорости в 15 раз. Принципиальное отличие лишь в том, что AMP – это HTML, а Турбо-технология реализована через XML-документы.
Здесь важно отметить, что ни АМP, ни турбирование напрямую не влияют на ранжирование (сайт не получает более высокие позиции просто из-за подключения быстрых страниц). Вместе с тем и в Google, и в Яндексе такая оптимизация дает опосредованные плюшки, влияющие на кликабельность onSERP, например, это расширенный сниппет на выдаче или маркировка страницы значком быстрой загрузки.
Читайте по теме:
Онлайн-коммерция на турбо скорости. Руководство по турбо-страницам Яндекса для магазинов
Таким образом, в случае с Турбо- и AMP-технологиями все фактически сводится к одному главному преимуществу – скорости. Но в угоду ей придется пожертвовать брендированным дизайном, оригинальным функционалом на странице; дополнительно это повлечет сложности с интеграцией рекламы и потенциальные проблемы с обработкой статистики. Это одинаково актуально и для быстрых страниц Яндекса, и для Google. Возможно, именно поэтому об этих двух технологиях сейчас упоминают намного реже, чем когда они только появились.
В Яндексе тег <noindex> или его валидный аналог применяют для закрытия части контента от индексации. В Google этот прием не работает: фрагмент документа, заключенный между этими тегами, будет обрабатываться поисковиками. Вместе с тем и с Яндексом все не так просто: с целью исключить манипуляции со спамом, noindex здесь работает как запрещающая директива для индексирования, но закрытый текст обрабатывается алгоритмами в антиспаме.
Директивы файла robots.txt – это список команд, при помощи которых поисковым роботам разрешают или запрещают сканировать весь сайт или отдельные его составляющие, прежде всего страницы. Во многом через грамотную работу с robots.txt можно влиять на позиции сайта в выдаче. Директивы для Google и Яндекса унифицированы, но есть исключения.
Так Google не поддерживает директиву Clean-param, которая в Яндексе указывает поисковым краулерам, что страница с GET-параметрами и метками не рекомендована к индексации. С 2019 года в обоих поисковиках не работает директива Crawl-delay (через нее задавали временные лимиты на сканирование, чтобы активность роботов не создавала нежелательных нагрузок на сайт). Стоит отметить и то, что Google более восприимчив к BOM-символу в robots (обычно он прекращает обработку файла).
В Google указать страну, к которой привязан сайт, можно только для gTLD-доменов общего назначения, например: .com, .edu, .gov и т. д. Это делают через вебмастерку Search Console. Для национальных ccTLD-доменов привязка страны происходит автоматически и скорректировать ее нельзя.
Яндекс присваивает регион для ccTLD-доменов по умолчанию. Его можно изменить в Вебмастере, если владелец сайта считает, что регион определен неверно, но для внесения изменений потребуется прохождение модерации. Для сайтов организаций настройку региональности дополнительно можно осуществить через заполнение данных в справочнике Яндекс.Бизнес. При желании такую привязку можно вовсе отключить.
На многих сайтах есть страницы с разными URL-адресами, но с дублированным или очень похожим содержимым. Через атрибут rel=«canonical» можно подсказать поисковым роботам, какая страница является приоритетной для индексации (канонической), а какие не рекомендованы к индексации (неканонические).
Оба поисковика по-разному группируют неканонические версии документов. Поисковые системы могут объединить в одну группу несколько похожих страниц, при этом назначить каноническими разные документы. А также оба поисковика по-разному производят склейку неканонических версий, например, в Google часть таких документов чаще залетает в индекс.
Стоит отметить и то, в Google можно осуществлять междоменную группировку, а также он умеет считывать атрибут canonical из XML-карты сайта.
Не все обратные ссылки одинаково полезны, и если на сайт ссылаются спамные домены (трэш-адалт, казино, фарма) – это плохие сигналы для поисковой репутации. Google предусмотрел механизм самостоятельного отклонения таких нежелательных ссылок – инструмент Disavow Tool. В Яндексе такой функционал отсутствует. Единственный вариант дезактивировать плохие обратные ссылки – списываться с админами сайта-донора, и просить их убрать линк.
При обработке Title – этот тег самый важный для SEO-оптимизации страницы – Google сканирует только первые 12 слов в заголовке (это гипотеза1, но с очень убедительной аргументацией). Яндекс же обрабатывает все слова в Title.
Что касается вхождения ключей, то здесь легко ступить на тонкий лед мифов и сомнительных предположений. Поэтому лучшее, что мы можем посоветовать на этот счет – внимательно анализировать, как оптимизированы тайтлы в топе по конкретному запросу (ключи, их плотность, указание ГЕО), и стараться сделать точно так же.
Атрибут ALT используют как альтернативное описание для картинок. В Яндексe он имеет значение только для поиска по картинкам, в то время как в Google способен влиять и на ранжирование в основной выдаче. В целом, атрибут ALT полезная вещь для SEO и там, и там, поэтому не стоит пренебрегать его заполнением.
Из нескольких одинаковых ссылок, ведущих на одну и ту же страницу, Google учтет исключительно первую, даже при условии разного анкора. Яндекс обработает все линки. Это касается как внутренних, так и внешних ссылок. Оптимизацию ссылочного профиля под Google и Яндекс важно проводить, учитывая подобные тонкости, особенно если вы занимаетесь закупкой дорогих трастовых ссылок.
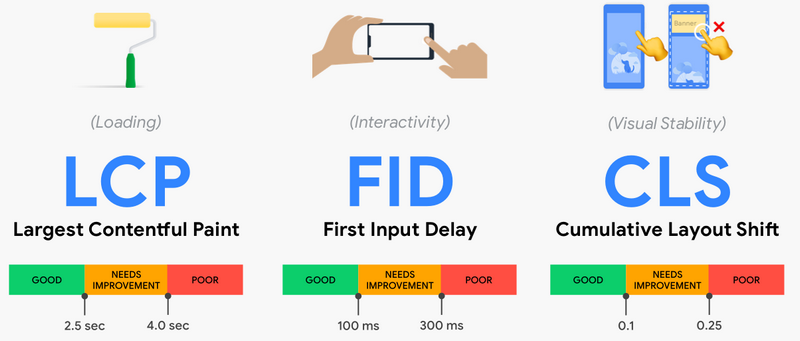
В целом оба поисковика используют более или менее схожие сигналы ранжирования. Но есть и отличия. Например, с лета 2021 Google стал ощутимо требовательнее относится к показателям производительности страниц. Для их оценки он использует группу метрик Core Web Vitals. Сюда входит три ключевых параметра:
LCP — метрика показывает, сколько времени уходит на отображение наиболее тяжеловесного элемента на странице (обычно это изображения). Оптимально: 2.5 сек. и меньше.
FID — показатель определяющий, насколько подвисает страница при первом взаимодействии (например, нажатии на ссылку или кнопку). Оптимально: меньше 100 мс.
CLS — метрика показывающая, насколько прыгает страница в полностью подгруженном состоянии. Оптимально: меньше чем 0.1.
Проверить сайт на соответствие показателям Core Web Vitals можно при помощи сразу нескольких гугловских инструментов:
Яндекс пока не относится столь серьезно к производительности страниц как фактору ранжирования.
Экспертность, авторитетность и достоверность (E-A-T) играют решающую роль для эффективного продвижения сайтов в Google. Главным образом это кается YMYL-сайтов, чья тематика напрямую влияет на здоровье и благосостояние пользователей. Больше на эту тему – здесь.
Яндекс, пусть и в весьма упрощенном виде, раскатывает похожую концепцию. Новые сигналы, внедренные в метрику качества поиска Proxima, призваны пересмотреть подходы к ранжированию в таких тематиках, как медицина, финансы и юридические услуги. В то же время обвалов подобно «Медицинскому апдейту» в поиске Яндекса не было.
Как бы неоднозначно ни воспринимался сам термин «песочница», факт остается фактом: сайт-новорег не будет получать органический трафик сразу после запуска. В Google это может затянуться на год и более. В Яндексе выход из «песочницы» обычно происходит быстрее: первый стабильный трафик из поиска здесь можно начать получать через пять-семь месяцев. Дополнительно у российского поисковика есть алгоритм «Многорукий бандит», который на время выводит в топ новореги, чтобы проанализировать пользовательский отклик. Если по метрикам все ок, молодой сайт начнет полноценно ранжироваться намного быстрее.
Впрочем, сегодня почти все вебмастера стараются избежать столь длительного простоя после старта. Созданию новорега большинство предпочитает запуск сайта на дропе (б/у домене, который уже имеет поисковую репутацию). Второй сценарий – поисковый буст новорега через подклейку одного или нескольких тематических дропов к основному домену. Обе схемы одинаково хорошо отрабатывают как в Google, так и в Яндексе.
Google очень не любит скрытый контент, и в главным образом это касается текстов, как основного инструмента seo-манипуляций. Вне зависимости о того, как технически реализовано такое скрытие (спойлеры, которые можно открывать, табы-переключатели и пр.), подобный контент будет пессимизирован. Дополнительно такие фрагменты не смогут подтягиваться в сниппеты или блоки быстрых ответов. Яндекс не практикует каких-либо ограничений по отношению к скрытому контенту.
В Google улучшение ранжирования после получения сильных сигналов происходит не сразу, а с определенной отсрочкой. Здесь работает т. н. функция перехода. Например, при получении качественной обратной ссылки от трастового донора позиции страницы-акцептора улучшаться не сразу, более того, они могут даже просесть. Положительные изменения будут доступны только спустя несколько месяцев. Так Google противодействует спамным техникам продвижения. Дополнительно эта механика помогает определять документы и сайты, использующие seo-манипуляции.
Google подчиняется закону DMCA, контролирующему авторское право в интернете. Здесь довольно исправно работает механика удаления из поиска страниц с заимствованным контентом. Если у вас украли текст/картинку/медиа, вы можете написать абузу в DMCA, и Google скроет страницу из основных результатов поиска. Такую же абузу могут написать и на вас. Эта опция доступна для всех, включая нерезидентов США.
На практике эффективность этого механизма весьма сомнительная, поскольку за владельцем сайта, на который написана жалоба, остается право подачи встречного уведомления. Естественно, большинство этим пользуется. Тогда Google возвращает забаненные страницы из скрытых результатов, и начинается долгая волокита. В теории все должно закончиться судебным разбирательством, до которого на практике редко доходит дело.
Яндекс подчиняется российскому законодательству и может банить сайты только по требованию Роскомнадзора.
Google подтягивает в сниппет содержимое meta-description, если в нем присутствуют слова из запроса, который ввел пользователь. Яндекс генерирует описание на выдаче более непредсказуемо. Чаще всего сюда подтягивается фрагмент из текста, который алгоритмы считают наиболее релевантным исходному запросу.
Сам по себе meta-description, вероятнее всего, уже давно не оказывает прямого влияния на ранжирование (заспамливать его ключами не имеет смысла), но его ценность как элемента, который формирует цельный и информативный сниппет – очевидна.
Существует множество вариаций семантической разметки стандарта Schema.org, но не все они поддерживаются в конкретных поисковых системах. Так в Яндексе не работает структурирование данных FAQpage (разметка страницы под часто задаваемые вопросы). А также в Яндексе нельзя разметить сниппеты, чтобы в них отображались хлебные крошки или звездочки рейтинга. В то же время сюда может подтянуться другая дополнительная информация, например, с Я.Маркета или турбированных страниц.
Более подробно, что работает в Google, а что – в Яндексе.
Дополнительно Google поддерживает (и рекомендует к использованию!) формат микроразметки JSON-LD. У Яндекса на этот счет дела пока обстоят так:
